
調べたいこと
SSDSE(教育用標準データセット)の家計消費データセットから、納豆の消費量が東日本と西日本で明らかに差があるかを調べる。
一般的なイメージだと、東日本の方が西日本より有意に消費量が多そう。
方針
・家計消費データセット(SSDSE-C)を読み込み、必要なデータだけを取り出す。(都道府県、世帯人員、納豆)
・(納豆)を(世帯人員)で割り、(世帯1人あたりの納豆消費量)を出す。
・都道府県ごとに東日本、西日本のカテゴリ変数を振り分ける。
・東日本と西日本でそれぞれ納豆消費量を可視化してみる。
・東日本の1人当たり納豆消費量の平均値、西日本の平均値を対応の無い2標本t検定にかけ、有意差があるか見てみる。
実装
ライブラリとデータの読み込み。ヘッダ行は元データの2行目を使い、データ部で都道府県が「全国」になっているデータは削る。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlibdf = pd.read_csv('./data/SSDSE-C-2024.csv')
df.head()#2行目をヘッダにして、全国の行を削除する
df = pd.read_csv('./data/SSDSE-C-2024.csv',skiprows=1)
df = df.drop(0)
df = df.reset_index()
df.head()
今回の検証で使用する項目だけを抜き出す。
#必要な列のみ取り出し
df = df[['都道府県','世帯人員','納豆']]
df.head()
都道府県ごとに平均世帯人員が異なるので、消費量を世帯人員でならす。
#世帯人員1人あたりの納豆消費量を計算
df['納豆_1人当たり'] = df['納豆'] / df['世帯人員']
df.head()
各都道府県のレコードに対して、東日本または西日本のカテゴリを付与する。
#東西日本に分けるためのlistを定義
east = ['北海道','青森県','岩手県','宮城県','秋田県',
'山形県','福島県','茨城県','栃木県','群馬県',
'埼玉県','千葉県','東京都','神奈川県','新潟県',
'山梨県','長野県','静岡県']
west = ['石川県','富山県','福井県','岐阜県','愛知県',
'三重県','滋賀県','京都府','大阪府','兵庫県',
'奈良県','和歌山県','鳥取県','島根県','岡山県',
'広島県','山口県','徳島県','香川県','愛媛県',
'高知県','福岡県','佐賀県','長崎県','熊本県',
'大分県','宮崎県','鹿児島県','沖縄県']
#東西カテゴリを追加
df['東西'] = ''
df.head()#カテゴリ振り分け関数
def match_category_fromlist(df,A,listA,B,C):
"""dfの項目Aについて、listの項目と突合して
一致した項目があれば項目BにカテゴリCを付与する
"""
for i in range(len(df)):
for j in range(len(listA)):
if df[A][i] == listA[j]:
df[B][i] = C
return df#振り分け処理
df = match_category_fromlist(df,'都道府県',east,'東西','東')
df = match_category_fromlist(df,'都道府県',west,'東西','西')※振り分け処理の詳細については以下を参照。

東西のカテゴリ変数を付与することができた。
都道府県別で納豆消費量を並べて見てみる。
# 数値項目Cを降順ソート
df_sorted = df.sort_values(by='納豆_1人当たり', ascending=False)
# 棒グラフの描画
plt.figure(figsize=(8, 5))
sns.barplot(x='都道府県', y='納豆_1人当たり', data=df_sorted, palette="Blues_r")
# タイトルとラベルを設定
plt.title('都道府県別 納豆1人当たりの消費量', fontsize=14)
plt.xlabel('都道府県', fontsize=12)
plt.ylabel('1人あたりの納豆消費量(円)', fontsize=12)
plt.xticks(rotation=45, fontsize=7)
# 値を上に表示
#for index, row in enumerate(df_sorted.itertuples()):
# plt.text(index, row.'納豆_1人当たり' + 1, row.'納豆_1人当たり',rotation=45, ha='center', fontsize=10)
# 表示
plt.show()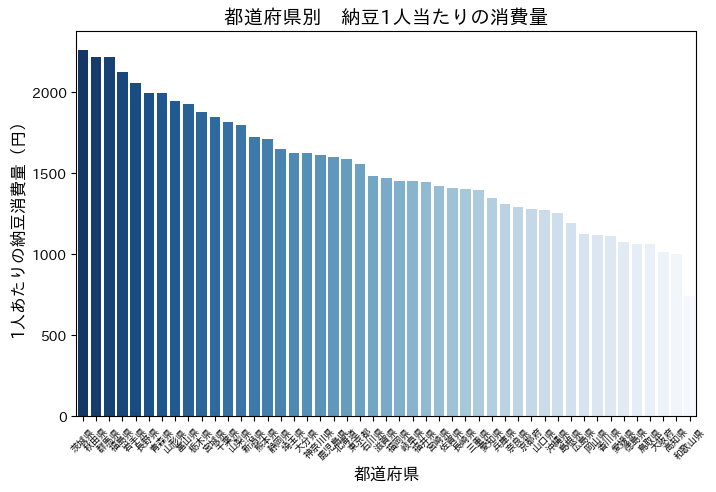
やはり茨城県が多い。ただ茨城県がダントツというわけではなく、秋田県、群馬県と肉薄している。また上位はほとんど東日本で、西日本で最も多いのは富山県で、それでも全体の9位である。
箱ひげ図を出力して東日本と西日本を比較してみる。
#まずは箱ひげ図で見てみる
plt.figure(figsize=(8, 5))
sns.boxplot(x='東西', y='納豆_1人当たり', data=df)
# タイトルとラベルを設定
plt.title('納豆消費量 東日本 vs 西日本', fontsize=14)
plt.xlabel('東西', fontsize=12)
plt.ylabel('1人当たり納豆消費量(円)', fontsize=12)
# 表示
plt.show()東日本の中央値と西日本の最大値がだいぶ近いので、これは有意差がありそう。
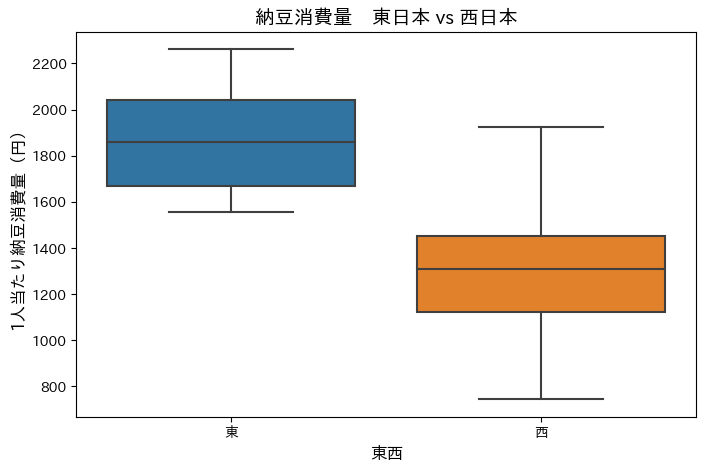
ここからデータを東西で2群に分け、有意差を検定していく。
#東西で2群に分割する。
df_east = df[df['東西'] == '東']
df_west = df[df['東西'] == '西']df_east = df_east.reset_index()
df_east.head()df_west = df_west.reset_index()
df_west.head()有意差検定の実行。両側検定(デフォルト)、等分散は仮定しないのでequl_varはFralseを指定する。
#有意差検定の実行
t_stat, p_val = stats.ttest_ind(df_east['納豆_1人当たり'], df_west['納豆_1人当たり'], equal_var=False) # Welchのt検定を使用
print(t_stat, p_val)実行結果はt≒8.03378、p=1.07893e-09。平均が等しいとする帰無仮説を棄却して有意差があると判断する。
結論
東日本の人たちは、西日本の人たちより明らかにたくさん納豆を食べる。
以上


コメント