やりたいこと
統計センターのオープンデータである「家計消費(SSDSE-C)」を用いて、品目ごとに東日本と西日本の消費量に有意差があるかを調べる。
特定の項目を取り出して個別にやるのではなく、数値項目すべてに対して有意差検定を行なっていく。
実装
前処理
数値項目について「世帯あたりの消費量」から「世帯1人あたりの」に変換し、各都道府県のデータに対して東西日本のカテゴリを付与する。
以下参考。


import pandas as pd
import numpy as np
import scipy.stats as statsdf = pd.read_csv('../00_data/SSDSE-C-2024.csv',skiprows=1)
df = df.drop(0)
df = df.reset_index()
df = df.drop('index',axis=1)
df.head()# 数値列のみを選択('世帯人員'は除く)
numeric_cols = df.select_dtypes(include=['number']).columns.drop('世帯人員', errors='ignore')
# 数値列を'世帯人員'で割る
df_numeric = df[numeric_cols].div(df['世帯人員'], axis=0)
# 数値以外の列をそのまま保持
non_numeric_cols = df.select_dtypes(exclude=['number']).columns
df_non_numeric = df[non_numeric_cols]
# 数値列と非数値列を結合
df = pd.concat([df['世帯人員'],df_non_numeric, df_numeric], axis=1)
df.head()#東西日本に分けるためのlistを定義
east = ['北海道','青森県','岩手県','宮城県','秋田県',
'山形県','福島県','茨城県','栃木県','群馬県',
'埼玉県','千葉県','東京都','神奈川県','新潟県',
'山梨県','長野県','静岡県']
west = ['石川県','富山県','福井県','岐阜県','愛知県',
'三重県','滋賀県','京都府','大阪府','兵庫県',
'奈良県','和歌山県','鳥取県','島根県','岡山県',
'広島県','山口県','徳島県','香川県','愛媛県',
'高知県','福岡県','佐賀県','長崎県','熊本県',
'大分県','宮崎県','鹿児島県','沖縄県']
#東西カテゴリを追加
df['東西'] = ''#関数
def match_category_fromlist(df,A,listA,B,C):
"""dfの項目Aについて、listの項目と突合して
一致した項目があれば項目BにカテゴリCを付与する
"""
for i in range(len(df)):
for j in range(len(listA)):
if df[A][i] == listA[j]:
df[B][i] = C
return df#振り分け処理
df = match_category_fromlist(df,'都道府県',east,'東西','東')
df = match_category_fromlist(df,'都道府県',west,'東西','西')
df[['都道府県','東西']]前処理済みデータを得た。
検定の実行
データを東西日本で分割する。西日本のdf_westをhead出力すると富山県からのデータになっているのがわかる。
df_east = df.query('東西 == "東"')
df_east.head()df_west = df.query('東西 == "西"')
df_west.head()
数値項目のみのリストおよび検定結果を格納するdfを作成し、検定処理をリストの分だけ繰り返し行なっていく。ループ処理の中で検定結果を格納していく。
#検定対象を数値項目に絞る
numeric_columns = df_east.select_dtypes(include=['number']).columns
# 検定結果を格納するdfを作成
df_ttest_result = pd.DataFrame(columns=["項目名", "t値", "p値"])
# 各列に対して検定を行う
for column in numeric_columns:
# dfA[column] と dfB[column] の t 検定
t_stat, p_val = stats.ttest_ind(df_east[column], df_west[column], equal_var=False) # Welchのt検定を使用
#結果を格納
df_ttest_result = df_ttest_result.append({"項目名": column, "t値": t_stat, "p値": p_val}, ignore_index=True)
検定結果をp値ソートで表示する。
# 結果の表示
df_ttest_result = df_ttest_result.sort_values('p値')
df_ttest_result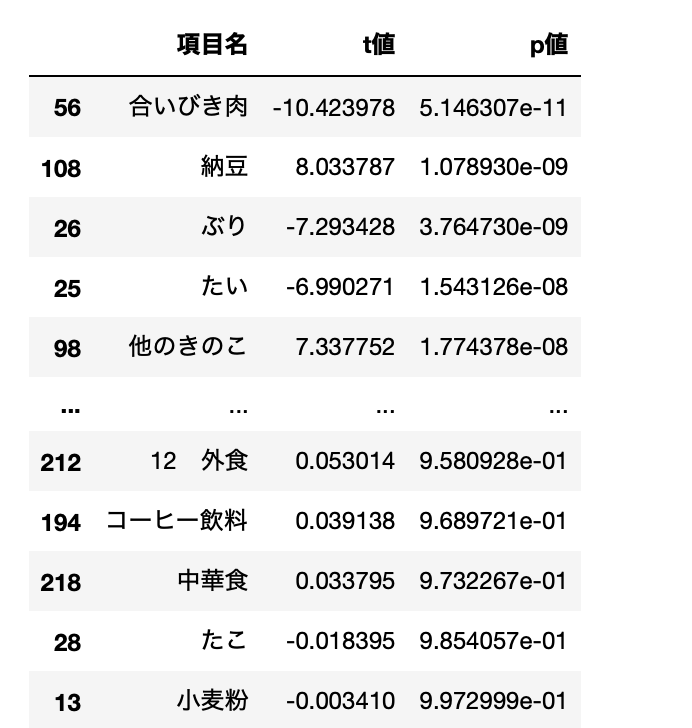
有意差があるといえる主な品目。納豆が東日本で有意に多く消費されているのはイメージ通りだが、それ以上に「合いびき肉」が西日本で圧倒的に消費量が多いのは意外であった。
| 品目 | 多い方 | t値 | p値 |
| 合いびき肉 | 西日本 | -10.423978 | 5.146307e-11 |
| 納豆 | 東日本 | 8.033787 | 1.078930e-09 |
| ぶり | 西日本 | -7.293428 | 3.764730e-09 |
| たい | 西日本 | -6.990271 | 1.543126e-08 |
| 他のきのこ | 東日本 | 7.337752 | 1.774378e-08 |
| 牛肉 | 西日本 | -6.834299 | 2.105600e-08 |
| 魚介の漬物 | 東日本 | 6.485334 | 6.283768e-08 |
| ウイスキー | 東日本 | 7.239762 | 7.119981e-08 |
| まぐろ | 東日本 | 6.903752 | 1.108080e-07 |
| やきとり | 東日本 | 6.403234 | 1.682398e-07 |
以上


コメント